
Placing sound masking on the front line of acoustic design

Photo © iStockphoto/Alexjay
Sound masking
A sound masking system—often mistakenly referred to by the term ‘white noise’—consists of a series of electronic components and loudspeakers integrated in a grid-like pattern above the ceiling, as well as a method of controlling their zoning and output. The loudspeakers distribute a sound similar to softly blowing air, causing many occupants to presume HVAC is its source. However, unlike HVAC, this sound is continuous and professionally tuned to meet a particular spectrum—or ‘curve’—engineered to balance acoustic control and occupant comfort.
Considering sound masking has been available since the late 1960s, one might wonder why the building community has yet to embrace it as the foundation for interior planning. To understand this delay, one has to consider the technology’s history.
Sound masking was first adopted to help with the obvious acoustic challenges encountered in an ever-growing number of open-plan spaces. This initial application led some to conclude it was only intended for these areas—an opinion reinforced by a significant technical impediment. Early systems used a centralized architecture, which is very limited in terms of its ability to offer local control over the masking sound. Zones containing large numbers of loudspeakers spanned numerous private offices and other closed rooms, with little opportunity to adjust the volume within each space (i.e. simply via 3-dBA transformer taps), and none for frequency. The resulting inconsistencies in volume and spectrum impacted the sound’s performance and occupant comfort, leading both vendors and dissatisfied users to conclude it could not be applied to closed spaces.
Advances made in sound masking technology—particularly decentralization of sound generation, volume, and frequency control, as well as the introduction of computer auto-tuning—mean minimum background sound level is now a readily deliverable component of architectural acoustic design.
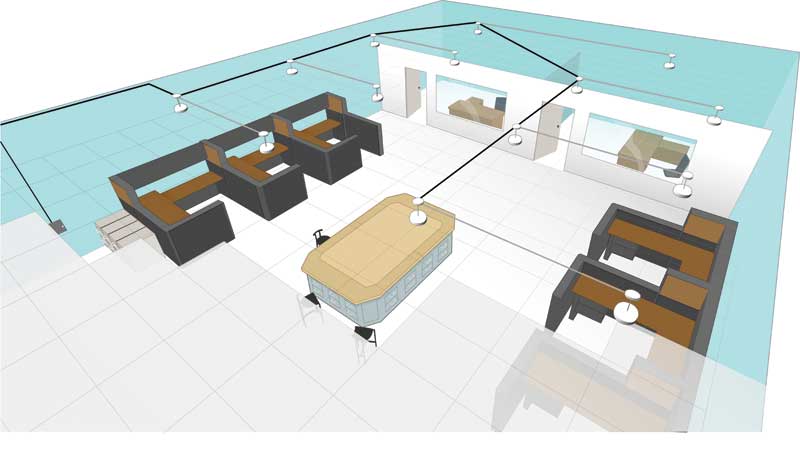
Image courtesy KR Moeller Associates Ltd.
The formula
ASTM E2638 expresses SPC as the sum of LD(avg) + Lb(avg), where LD is average reduction in source level at the listening position (i.e. transmission loss) and Lb is the average background sound level at the listening position. While preparing “Sound & Vibration 2.0: Design Guidelines for Health Care Facilities”—the companion document to the Facility Guidelines Institute’s (FGI’s) 2014 Guidelines for Design and Construction of Hospitals and Outpatient Facilities—acousticians simplified this formula, declaring to “achieve confidential speech privacy the sum of the composite STC and the A-weighted background noise level shall be at least 75,” or STCc + dBA ≥ 75. The composite STC (STCc) metric includes the negative impact on acoustic performance when elements such as doors and windows are added to the partition.
Some refer to this revised method as speech privacy potential (SPP) and, indeed, it provides a basic predictive model for achieving speech privacy in closed rooms. As dBA is assumed to be 30, STCc must be at least 45 to achieve the combined total of 75. Using sound masking to apply a continuous level of 30 dBA eliminates the variability of the source, and speech privacy is more reliably achieved with the stated STCc. The curve generated by a well-designed and professionally tuned masking system is also precise; therefore, the speech privacy it provides is greater than the typically erratic spectrum produced by HVAC equipment, even at the same volume.
However, in this scenario, it is important to note the sound is set to a level far below that used in traditional masking applications. Leaving a range of adjustment ‘on the table’ provides two additional advantages—cost savings and flexibility.
Sign up for our weekly newsletter
Construction Canada weekly newsletters give the latest AEC industry news for those who build, design, engineer, specify, renovate or operate in the built environment.
Products & Services





Read the Latest Issue
